SmartCSV.fx version 0.6
Posted on August 8, 2016
Refactored the validation algorithm to improve maintainability.
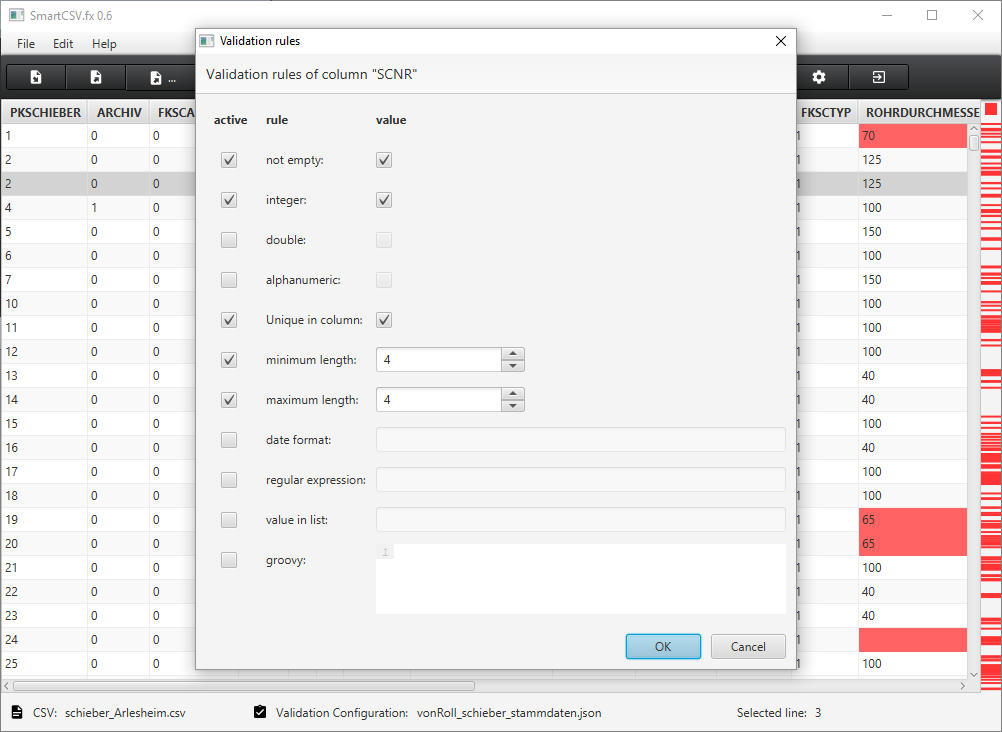
As the interest in the project grows, I revisited the validation algorithm and refactored it.
Uniqueness rule in version 0.5
I introduced an uniqueness feature in version 0.5. This was the first validation, which has to include all the other values in a column for the check. This validation is slower than the validation of a single value against a simple rule. So I decided to try to improve the performance.
Old code
The old version of the validation algorithm walks through every possible validation rule and asks the configuration if the validation is active for the current column.
|
|
This results in a lot checks.
|
|
Refactored code
All checks were done in a single validation class, which was straight forward, but with more validation rules, it was harder to maintain.
So I refactored the whole validation algorithm.
Each validation rule was implemented as an own class like strategy pattern.
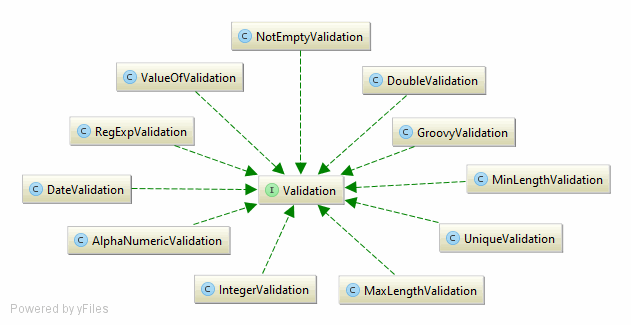
All active validation rules for an column are stored in a list (value list of the HashMap).
|
|
The isValid() method just iterates over the active rules in the list.
|
|
With that design, it is a lot easier to implement new validation rules and the performance is much better as only the active rules for a column are used.